How To Imort All Kinds Of Files Into Scrivener
Scrivener File Import
In this article I’m going to show you a bunch of different import options for Scrivener, many of which have made MY life a lot easier and I want to share them with you.
Here’s what we’ll be going through:
• How to import and use almost every kind of file inside Scrivener
• Which text file types are supported
• How you can easily import web pages and use them inside Scrivener
• How to link to external files in order to keep your project size small
• How to import MultiMarkdown files
• The difference between importing plain text and fountain files
• How to automatically split documents when importing, this one is really awesome
You see, there’s a lot of ground to cover today, so let’s jump right into it.
Importing All Kinds of Files
Most simple thing ever, go to “File – Import – Files”. Basically, you can import anything you like into Scrivener. The only question is: do you want to read or edit it in some way inside Scrivener.
This is what you need to know: You can only import text files, and picture files to some extent, into the draft folder. Every other file has to go to another folder outside of the draft folder. By default it’s called the “Research” folder but you can rename it anyway you like. Or add additional folders.
You can import the following text file formats into the binder:
• RTFD, which is a proprietary Apple rich text format
• RTF, which is standard rich text
• DOC and DOCX word files
• ODT open text documents
• TXT plain text documents
• PDF for read only, they have to go outside the draft folder
• Html
• FDX or FCF Final Draft files
• Fountain plain text files
• OPML Files: some outlining programs use this format to handle outline trees
• Indexcard files form the iPad
• Files without extension
Most text files that are imported are internally converted into rich text documents or plain text files, depending on how you set it up, which are then stored inside the Scrivener project.
Importing Web Pages
So what about web pages? You can import them as well, with pictures and all. Go to “File – Import – Web Page”. The page is then archived inside the project and is available offline. This only works outside the draft folder by the way. Many web pages remain fully functional after you import them. So this gives you an easy way to have your web sources inside the project, but you can still use the web links if you want to go to that page quickly.
Linking to Research Material
Everything you import into Scrivener is stored inside the project as a copy. The advantage is you have all your files in one place. But there are also disadvantages. You might want to work with outside file sources that are updated regularly. Or, you might need big files, for example audio or video files, that increase the file size and the backup space of your Scrivener project.
The solution to this is to import Alias links to those files instead of the file itself. To do this, go to “File – Import – Research Files as Aliases”. Those files are now only referenced to and you can still use and update them outside of Scrivener.
Imported Aliases are displayed with a small arrow in the lower-left corner of the icon. If the linked files are moved, the link will update accordingly, unless you move them to another computer. In that case, Scrivener still keeps the meta data of those files in the project. Due to technical reasons this only works for non-text files that Scrivener can display in the editor.
MultiMarkdown File
MultiMarkdown Files. MultiMarkdown is a markdown language that lets you create html code from text documents very easily. If you want to know more about it go to multimarkdown.com. You also have the link in the description below, so just go there and click on that. If you import a MultiMarkdown file, Scrivener will create a new file in the binder for every MultiMarkdown header.
Plain Text Screenplay
Don’t confuse this with importing fountain, which I will explain in a second. This function is for simple text documents or for importing plain text screenplays, for example from Movie Magic Screenwriter or other screenwriting applications. In this case Scrivener will do the screenplay formatting for you as much as possible.
Scrivener Project
You can also import a whole Scrivener project into your binder. Scrivener will create an “Imported Project” folder with the project name and it keeps the whole binder structure intact, including keywords and other meta data. Your notes will be imported into a “Project Notes” folder, placed conveniently at the top of the main import folder here.
This is especially useful if you need to restore a corrupt project. If you have a project that you can’t open anymore, try importing it into another Scrivener project and the program will try to restore as much from it as possible.
Import and split
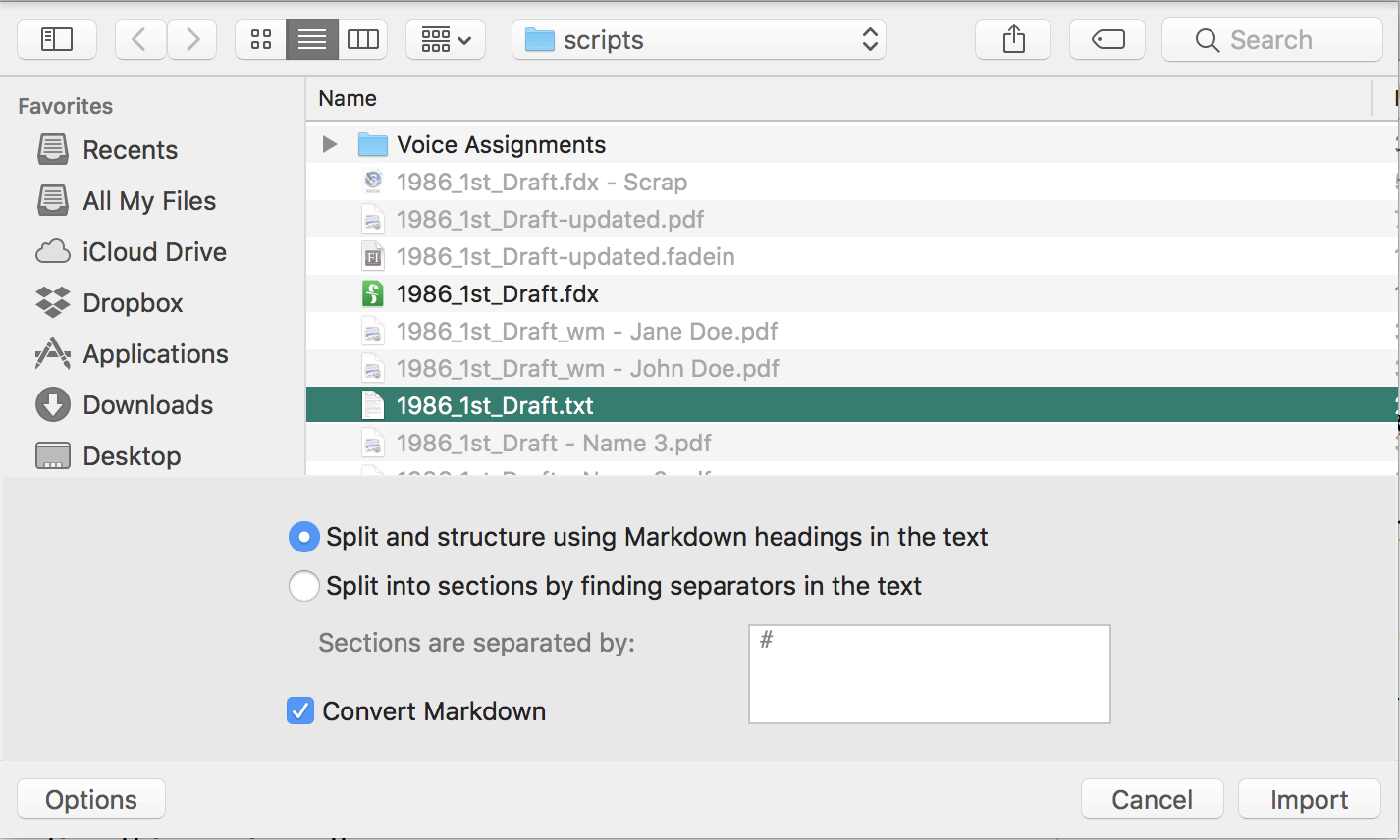 Now, this is function that will save you a lot of time. This basically chops up your document in subdocuments by certain rules and automatically names your files. There are three ways to use this:
Now, this is function that will save you a lot of time. This basically chops up your document in subdocuments by certain rules and automatically names your files. There are three ways to use this:
TXT or RTF Files
You can split your document by a certain separator that you define in the import dialog. Just enter the character you want Scrivener to look for here in the box. Lines containing ONLY this character will be completely removed during import. Also, a part of the first line of each part of the document will be used to create a document title.
FDX and FCF Final Draft Files
This lets you easily break up your script into single pieces at whichever script format element you want. Most likely you will use scenes here. Select “Scene Heading” and Scrivener will create one document per scene and convert the formatting into its own script elements. Your scene title will become the name of the scene document and the scene summary from Final Draft becomes the Scrivener synopsis.
Fountain Files
If you use the .fountain file extension, Scrivener will automatically split your file by scene. The slug line name will also become your scene name.
Alright, so you see there are a lot of different options, so whatever it is that you want to import, just play with this a little if you don’t get it right the first time.